Informatika

Nem csak a MySQL mûködik igy, az autoincrement oszlop attól az, hogy sosem csökken az értéke (de be lehet állítani tetszõlegesre), adatbázistól (MySQL, MSSQL stb) függetlenül.
Bontsuk kétfelé a dolgot:
1. Logika: A lyukak azért vannak ugye, mert az autoincrement PK oszlopod folyton növekszik eggyel, hiába törölsz belõle. Ennek több oka is van, az adatbázis teljesítményét jól indexelt táblák esetén nem érinti számottevõen, viszont pl. az adatok beírásának kronológiai sorrendjét megtartja, ami hasznos lehet.
Ha nem autoincrement oszlopot használsz primary keynek, hanem pl egy GUID oszlopot (PHP, Java, MS nyelvek mind tudnak ilyet generálni, mert a MySQL nem támogatja ezt a tipust, csak úgy, ha csinálsz egy char(36) oszlopot), akkor egyrészt nem lesznek logikai lyukak, másrészt lényegesen biztonságosabb lesz az adatbázisod, ugyanis nem lehet próbálgatással, de még generálással sem kitalálni id-kat a táblából.
Pl az itteni fórumnál (nem biztonsági kérdés, csak egy példa) a válaszadás úgy megy, hogy az URL végén van egy ref=38 (jelen esetben) string, azaz én most a 38-as id-val rendelkezõ beírásra válaszolok.
Ha elkezdem próbálgatni a számokat, elvben találhatok olyan hozzászólást, ami egyébként nem jelenhetne meg sehol, igy tudok rá válaszolni.
Ennek itt nincs nagy jelentõsége, de pl egy terméklistánál már lehet.
Ha viszont a hozzászólásokat GUID PK-val mented el, akkor esélyem sincs rá - vagy csak nagyon kicsi esély van - , hogy kitaláljam egy bármelyik másik hozzászólás GUID-ját, vagy próbálkozással rátaláljak egy elrejtett beírásra.
Ráadásul a PK azt jelenti, hogy a tábla sorai a fizikai tárolón is eszerint rendezve tárolódnak le (már ha van értelme a rendezésnek), tehát ha elkezdene insertkor beszurkálni a lyukakba, akkor nagyon lassítaná magát.
2. Fizikai hely: Itt valóban lyukak maradnak, de nem csak a MySQL-nél, hanem MS SQL-ben is, ezt pl shrink/reorganize tudja eltüntetni, pl az SQL 2005 Management Studio-val.
Nem beszéltem a fizikai lapméretrõl még, ami igencsak befolyásolja az adatbázis teljesítményét (pl 100 sornyi adat hány lapon van) - pontosabban az hogy hogy sikerül a lapmérethez minél jobban alkalmazkodva tárolni az adatokat, meg az indexek fill factor-áról, ezek is befolyásolják a teljesítményt.
Bontsuk kétfelé a dolgot:
1. Logika: A lyukak azért vannak ugye, mert az autoincrement PK oszlopod folyton növekszik eggyel, hiába törölsz belõle. Ennek több oka is van, az adatbázis teljesítményét jól indexelt táblák esetén nem érinti számottevõen, viszont pl. az adatok beírásának kronológiai sorrendjét megtartja, ami hasznos lehet.
Ha nem autoincrement oszlopot használsz primary keynek, hanem pl egy GUID oszlopot (PHP, Java, MS nyelvek mind tudnak ilyet generálni, mert a MySQL nem támogatja ezt a tipust, csak úgy, ha csinálsz egy char(36) oszlopot), akkor egyrészt nem lesznek logikai lyukak, másrészt lényegesen biztonságosabb lesz az adatbázisod, ugyanis nem lehet próbálgatással, de még generálással sem kitalálni id-kat a táblából.
Pl az itteni fórumnál (nem biztonsági kérdés, csak egy példa) a válaszadás úgy megy, hogy az URL végén van egy ref=38 (jelen esetben) string, azaz én most a 38-as id-val rendelkezõ beírásra válaszolok.
Ha elkezdem próbálgatni a számokat, elvben találhatok olyan hozzászólást, ami egyébként nem jelenhetne meg sehol, igy tudok rá válaszolni.
Ennek itt nincs nagy jelentõsége, de pl egy terméklistánál már lehet.
Ha viszont a hozzászólásokat GUID PK-val mented el, akkor esélyem sincs rá - vagy csak nagyon kicsi esély van - , hogy kitaláljam egy bármelyik másik hozzászólás GUID-ját, vagy próbálkozással rátaláljak egy elrejtett beírásra.
Ráadásul a PK azt jelenti, hogy a tábla sorai a fizikai tárolón is eszerint rendezve tárolódnak le (már ha van értelme a rendezésnek), tehát ha elkezdene insertkor beszurkálni a lyukakba, akkor nagyon lassítaná magát.
2. Fizikai hely: Itt valóban lyukak maradnak, de nem csak a MySQL-nél, hanem MS SQL-ben is, ezt pl shrink/reorganize tudja eltüntetni, pl az SQL 2005 Management Studio-val.
Nem beszéltem a fizikai lapméretrõl még, ami igencsak befolyásolja az adatbázis teljesítményét (pl 100 sornyi adat hány lapon van) - pontosabban az hogy hogy sikerül a lapmérethez minél jobban alkalmazkodva tárolni az adatokat, meg az indexek fill factor-áról, ezek is befolyásolják a teljesítményt.
Havazás előrejelzés

Utolsó észlelés
Térképek
Radar
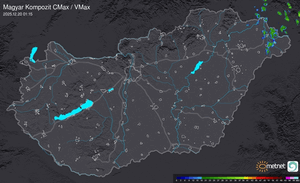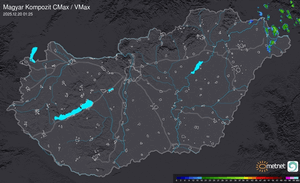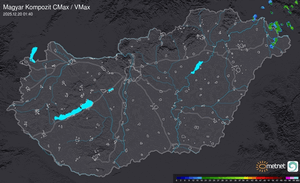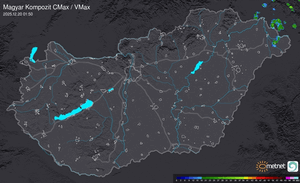
Aktuális hõmérséklet
Aktuális szél
Utolsó kép

2026. Március 23. - Meteorológiai Világnap
MetNet | 2026-03-22 17:25
Szabályzat